0
vistas


Ultima actualización en

Wayback Machine es la parte más popular de la Sitio web de Internet Archive. Presentada por primera vez en 2001, la herramienta en línea gratuita le permite "retroceder en el tiempo" para ver cómo se veían los sitios web de todo el mundo en determinados momentos. La Wayback Machine cuenta con 562 mil millones páginas web en el momento de escribir este artículo, y cada año se agregan muchas más.
Aquí hay un vistazo a la Wayback Machine y lo que la hace especial.
Creado por Brewster Kahle y Bruce Gilliat, Internet Archive es una organización sin fines de lucro con la misión declarada de "acceso universal a todo el conocimiento". Desde el principio, la organización ha proporcionado acceso público gratuito a materiales digitalizados, como páginas web, libros, grabaciones de audio, incluidos conciertos en vivo, videos, imágenes y software programas.
Hasta la fecha, todo lo recopilado por Internet Archive ocupa más de 70
Solo una parte del Archivo de Internet, Wayback Machine, se diseñó para capturar el contenido del sitio web que ha cambiado o eliminado. Desde su lanzamiento, se ha convertido en uno de los lugares más populares y reconocidos de la web. Kahle y Gilliat nombraron el sitio en honor al dispositivo ficticio que viaja en el tiempo en la serie animada de la década de 1960, The Rocky and Bullwinkle Show.
Aunque Internet Archive no lanzó el sitio al público hasta octubre de 2001, Wayback Machine comenzó a archivar páginas web almacenadas en caché a partir de mayo de 1996. Hasta 2001, las cintas digitales almacenaban información a la que solo podían acceder determinados científicos e investigadores. Cuando todo salió al público cinco años después (como estaba planeado durante mucho tiempo), ya había contenido más de 10 mil millones de páginas archivadas.
Hoy en día, el sitio mantiene datos web históricos en un grupo de nodos de Linux. Wayback Machine descarga toda la información y los archivos de datos de acceso público en las páginas web a través de su mecanismo de rastreo. Sin embargo, no todo lo que se publica en un sitio web se incluye aquí, ya que parte del contenido está restringido o almacenado en bases de datos a las que no se puede acceder. Debido a esto, algunos sitios web se rastrean mejor que otros, dependiendo de cómo los desarrolladores crearon un sitio a la vez.
También notará que cuanto más nuevo es el archivo, más contenido está disponible para un sitio determinado. Una nueva herramienta que Internet Archive introdujo en 2005 es una de las razones por las que los datos más recientes son más completos. Archive-It.org ayuda a superar las inconsistencias en sitios web parcialmente almacenados en caché al permitir que las instituciones y los creadores de contenido recopilen y conserven colecciones de contenido digital.
Los rastreadores web, a veces llamados araña o robot araña, son tan antiguos como Internet. Estos rastreadores son bots de Internet que navegan continuamente por la web con fines de indexación, lo que los convierte en un componente importante de cualquier motor de búsqueda moderno. Los rastreadores utilizados por Wayback Machine para crear instantáneas digitales de sitios web provienen de varias fuentes, que han cambiado con el tiempo.
Como notará rápidamente, la frecuencia de las capturas de instantáneas varía mucho según el sitio web. Por lo general, cuanto más grande (y quizás más popular) un sitio web, más rastreo se produce. Además, mucho depende de la frecuencia con la que un sitio web cambia de página. Incluso los sitios web más pequeños se rastrean con el tiempo, a menos que exista una razón por la que no lo sean. Por ejemplo, los sitios protegidos con contraseña no se rastrean, ni tampoco los sitios web cuyos propietarios han solicitado que no se incluyan.
El sitio web de Wayback Machine es fácil de usar para cualquier persona. Para encontrar instantáneas históricas de un sitio web, escriba su nombre en el motor de búsqueda del sitio. En la página de resultados de búsqueda, los hipervínculos indican las fechas y horas en que se archivó un sitio. Haga clic en el enlace para ver el sitio "atrás en el tiempo".
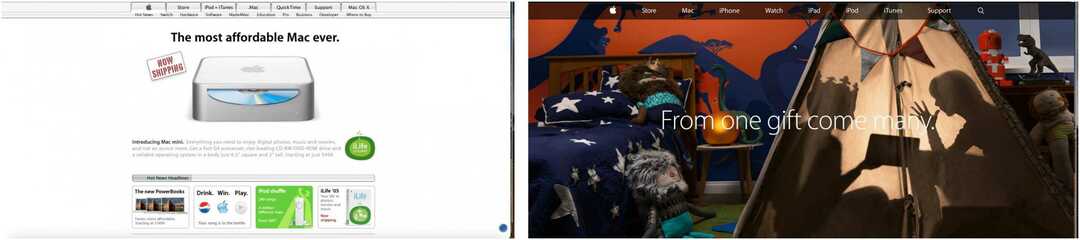
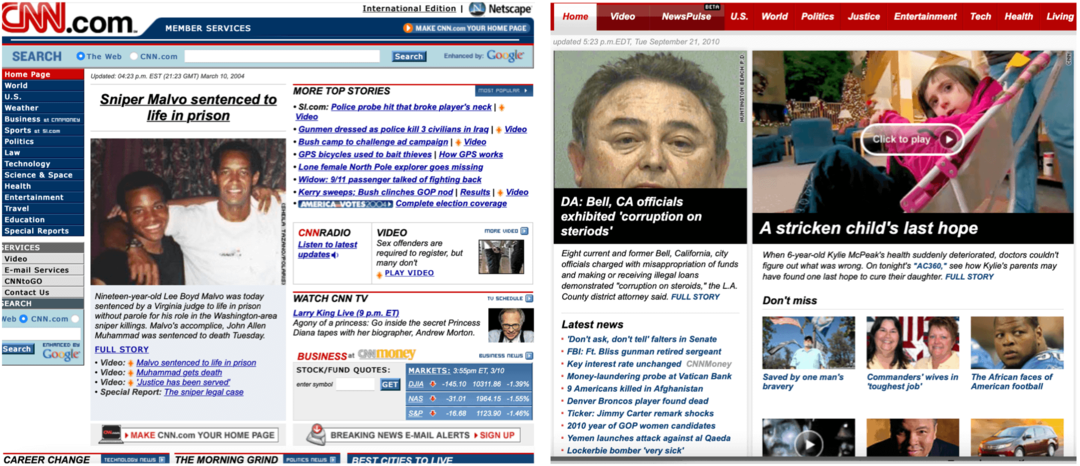
En los siguientes ejemplos, puede ver la página principal del sitio web de Apple registrada en febrero de 2005 y noviembre de 2014, y la página de inicio de CNN de una fecha en marzo de 2004 y septiembre de 2010.
Nota: Estos rastreos también incluyen enlaces a otras páginas registradas en las fechas indicadas, no solo a las páginas de inicio.
Creada para investigadores y para el público por igual, Wayback Machine tiene algunas herramientas integradas que los usuarios ocasionales pueden perder. Por ejemplo, por diseño, las páginas de resultados de búsqueda son fáciles de consultar. Como se explicó, “Si encuentra una página archivada a la que le gustaría hacer referencia en su página web o en un artículo, puede copiar la URL. Incluso puede utilizar la concordancia aproximada de URL y la especificación de fecha... pero eso es un poco más avanzado ".
Wayback Machine también permite a los propietarios de sitios utilizar la función "Guardar página ahora" para guardar una página específica. Y, sin embargo, no es perfecto. Actualmente, la función no agrega la URL del sitio a ningún rastreo futuro. Además, la solicitud no guarda más de una página. Sin embargo, es un buen primer paso archivar la página principal de su sitio web para el registro histórico.
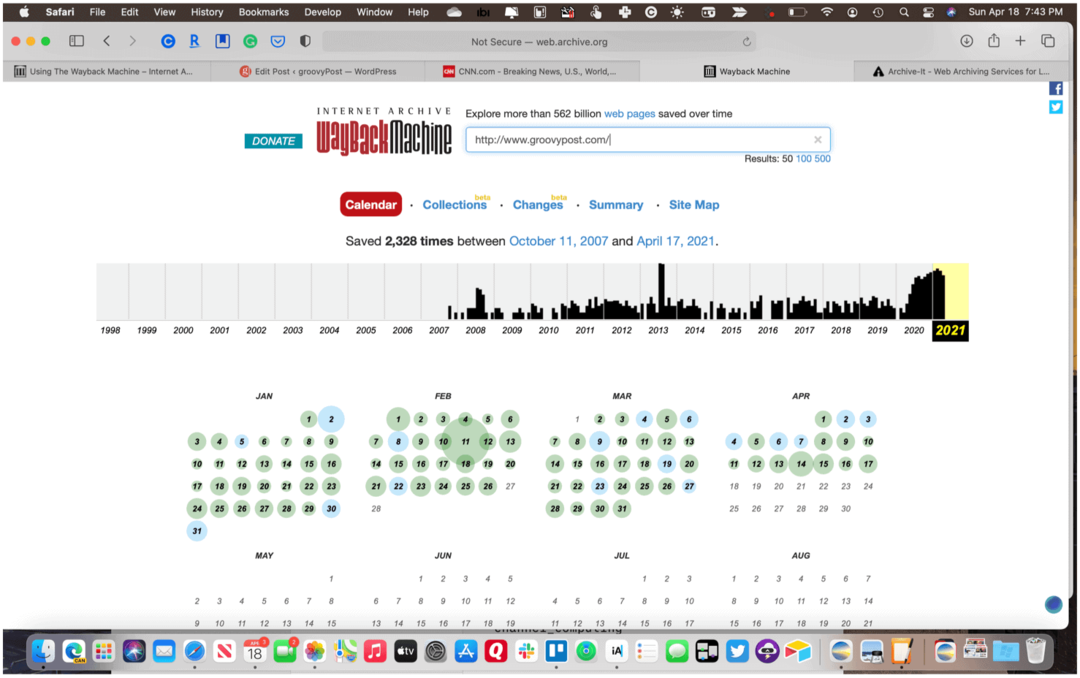
No es necesario que visite Wayback Machine cada vez que realice una nueva búsqueda. En su lugar, puede buscar contenido escribiendo la dirección en la barra de herramientas de su navegador web. Utilice este formato para todas las búsquedas: http://web.archive.org/*/www.yoursite.com/*. Por ejemplo, use http://web.archive.org/*/www.groovypost.com/* para encontrar páginas archivadas para GroovyPost!
Finalmente, Wayback Machine no solo se encuentra a través de la web. Puede encontrar una aplicación Wayback Machine para iOS y Androide. También hay extensiones para Chrome, Safari y Firefox. Los desarrolladores también querrán consultar las API de Wayback Machine de Internet Archive. Esto hace que sea más fácil para los desarrolladores recuperar información sobre los datos de captura de Wayback.
Internet Archive Wayback Machine admite varias API diferentes. Al hacerlo, facilita a los desarrolladores la recuperación de información sobre los datos de captura de Wayback.
Retroceder en el tiempo para sus sitios web favoritos es la razón número uno para visitar Wayback Machine. También es una gran herramienta para cualquier persona que busque el historial de un sitio web para proyectos escolares o para uso comercial. Hagas lo que hagas, visita Wayback Machine y descubre lo que puedes descubrir en unos sencillos pasos.
Para obtener más información sobre el servicio de suscripción Archive-It de Internet Archive, visite el página web oficial ¡y comience a contribuir hoy!

