124
vistas

Ultima actualización en

Uno de los mayores errores para los nuevos propietarios de sitios web es no buscar en su archivo robots.txt. Entonces, ¿qué es de todos modos y por qué es tan importante? Tenemos sus respuestas
Si posee un sitio web y se preocupa por el estado de SEO de su sitio, debe familiarizarse con el archivo robots.txt de su dominio. Lo creas o no, ese es un número inquietantemente alto de personas que inician rápidamente un dominio, instalan un sitio web rápido de WordPress y nunca se molestan en hacer nada con su archivo robots.txt.
Esto es peligroso. Un archivo robots.txt mal configurado en realidad puede destruir el estado de SEO de su sitio y dañar cualquier posibilidad que tenga de aumentar su tráfico.
los Robots.txt El nombre del archivo es adecuado porque es esencialmente un archivo que enumera las directivas para los robots web (como los robots de los motores de búsqueda) sobre cómo y qué pueden rastrear en su sitio web. Este ha sido un estándar web seguido por sitios web desde 1994 y todos los principales rastreadores web se adhieren al estándar.
El archivo se almacena en formato de texto (con una extensión .txt) en la carpeta raíz de su sitio web. De hecho, puede ver el archivo robot.txt de cualquier sitio web simplemente escribiendo el dominio seguido de /robots.txt. Si prueba esto con groovyPost, verá un ejemplo de un archivo robot.txt bien estructurado.
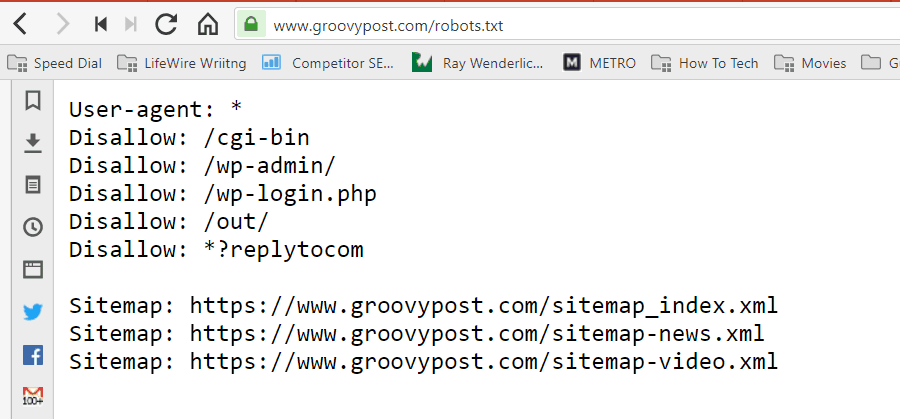
El archivo es simple pero efectivo. Este archivo de ejemplo no diferencia entre robots. Los comandos se emiten a todos los robots mediante el uso de Agente de usuario: * directiva. Esto significa que todos los comandos que siguen se aplican a todos los robots que visitan el sitio para rastrearlo.
También puede especificar reglas específicas para rastreadores web específicos. Por ejemplo, puede permitir que Googlebot (rastreador web de Google) rastree todos los artículos de su sitio, pero es posible que desee no permita que el rastreador web ruso Yandex Bot rastree artículos en su sitio que tengan información despectiva sobre Rusia.
Hay cientos de rastreadores web que buscan información sobre sitios web en Internet, pero los 10 más comunes por los que debe preocuparse se enumeran aquí.
Tomando el escenario de ejemplo anterior, si desea permitir que Googlebot indexe todo en su sitio, pero desea para evitar que Yandex indexe el contenido de su artículo basado en Rusia, debe agregar las siguientes líneas a su robots.txt archivo.
Agente de usuario: googlebot
No permitir: No permitir: / wp-admin /
No permitir: /wp-login.php
Agente de usuario: yandexbot
No permitir: No permitir: / wp-admin /
No permitir: /wp-login.php
No permitir: / rusia /
Como puede ver, la primera sección solo impide que Google rastree su página de inicio de sesión de WordPress y las páginas administrativas. La segunda sección bloquea Yandex de lo mismo, pero también de toda el área de su sitio donde ha publicado artículos con contenido anti-Rusia.
Este es un ejemplo simple de cómo puede usar el Rechazar comando para controlar rastreadores web específicos que visitan su sitio web.
No permitir no es el único comando al que tiene acceso en su archivo robots.txt. También puede usar cualquiera de los otros comandos que dirigirán cómo un robot puede rastrear su sitio.
Tenga en cuenta que los bots lo harán solamente escuche los comandos que ha proporcionado cuando especifica el nombre del bot.
Un error común que comete la gente es rechazar áreas como / wp-admin / de todos los bots, pero luego especifique una sección de googlebot y solo rechace otras áreas (como / about /).
Dado que los bots solo siguen los comandos que especifique en su sección, debe reexpresar todos esos otros comandos que ha especificado para todos los bots (usando el * user-agent).
Tenga en cuenta que el archivo robots.txt está destinado a ayudar a los bots legítimos (como los bots de los motores de búsqueda) a rastrear su sitio de manera más efectiva.
Hay muchos rastreadores nefastos que rastrean su sitio para hacer cosas como raspar direcciones de correo electrónico o robar su contenido. Si desea probar y usar su archivo robots.txt para evitar que los rastreadores rastreen algo en su sitio, no se moleste. Los creadores de esos rastreadores generalmente ignoran todo lo que haya puesto en su archivo robots.txt.
Lograr que el motor de búsqueda de Google rastree la mayor cantidad posible de contenido de calidad en su sitio web es una preocupación principal para la mayoría de los propietarios de sitios web.
Sin embargo, Google solo gasta una cantidad limitada presupuesto de rastreo y frecuencia de rastreo en sitios individuales. La frecuencia de rastreo es cuántas solicitudes por segundo hará el robot de Google a su sitio durante el evento de rastreo.
Más importante es el presupuesto de rastreo, que es la cantidad total de solicitudes que realizará el robot de Google para rastrear su sitio en una sesión. Google "gasta" su presupuesto de rastreo al enfocarse en áreas de su sitio que son muy populares o que han cambiado recientemente.
No eres ciego a esta información. Si tú visitas Herramientas para webmasters de Google, puede ver cómo el rastreador maneja su sitio.
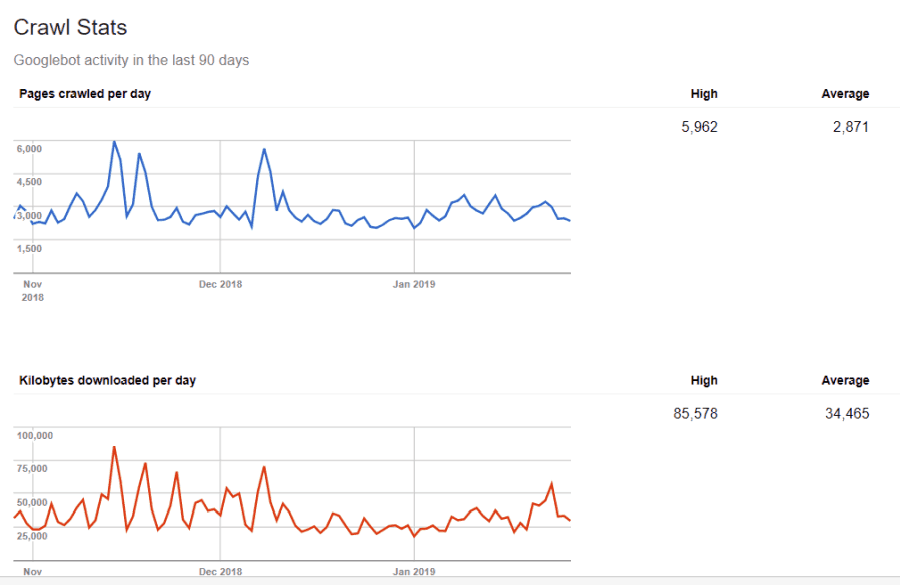
Como puede ver, el rastreador mantiene su actividad en su sitio bastante constante todos los días. No rastrea todos los sitios, sino solo aquellos que considera los más importantes.
¿Por qué dejar que Googlebot decida qué es importante en su sitio, cuando puede usar su archivo robots.txt para decirle cuáles son las páginas más importantes? Esto evitará que Googlebot pierda tiempo en páginas de bajo valor en su sitio.
Las Herramientas para webmasters de Google también le permiten verificar si Googlebot está leyendo bien su archivo robots.txt y si hay algún error.
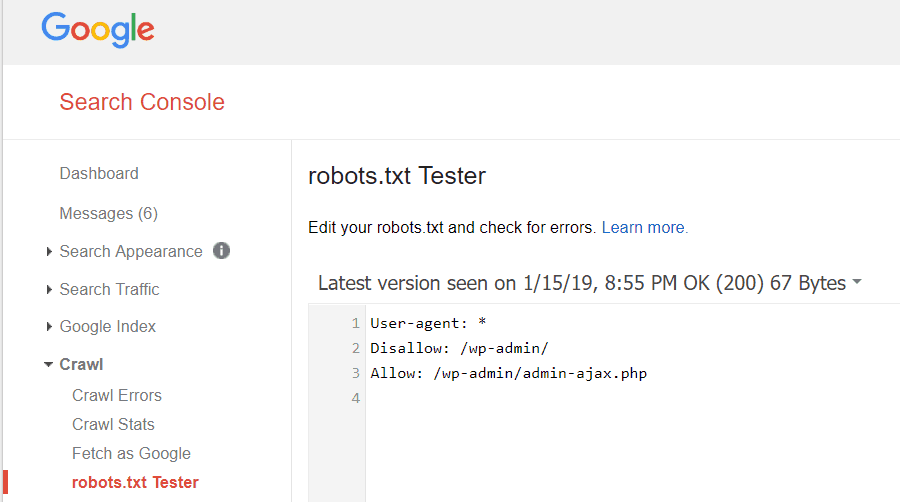
Esto le ayuda a verificar que ha estructurado su archivo robots.txt correctamente.
¿Qué páginas deberías rechazar de Googlebot? Es bueno que el SEO de su sitio no permita las siguientes categorías de páginas.
El mayor error que cometen los nuevos propietarios de sitios web es ni siquiera mirar su archivo robots.txt. La peor situación podría ser que el archivo robots.txt realmente esté bloqueando su sitio, o áreas de su sitio, para que no se rastree.
Asegúrese de revisar su archivo robots.txt y asegúrese de que esté optimizado. De esta manera, Google y otros motores de búsqueda importantes "ven" todas las cosas fabulosas que ofrece al mundo con su sitio web.